



I. Pourquoi CouchDB ?▲
Apache CouchDB est une nouvelle espèce de système de gestion de bases de données. Ce chapitre explique les raisons du besoin de nouveaux systèmes ainsi que les motivations sous-jacentes à la conception de CouchDB.
En tant que développeurs de CouchDB, nous sommes bien entendu très excités à l'idée de pouvoir utiliser CouchDB. Tout au long de ce chapitre, nous partagerons avec vous les raisons de notre enthousiasme. Nous vous montrerons pourquoi le modèle de document sans squelette de CouchDB est une meilleure solution pour les applications classiques, en quoi le langage de requête qu'il intègre par défaut est un moyen puissant d'utilisation et de traitement de vos données, et en quoi la conception même de CouchDB se prête à la modularisation et au passage à l'échelle.
I-A. Détendez-vous▲
S'il est un mot pour décrire CouchDB, c'est détendez-vous [NdT : en anglais, relax]. C'est le titre de ce livre, c'est le slogan du logo officiel de CouchDB, et quand vous démarrez CouchDB, vous voyez :
Apache CouchDB has started. Time to relax.Pourquoi la détente est-elle importante ? La productivité d'un développeur a environ doublé ces cinq dernières années. La principale raison de cette amélioration réside dans la facilité d'utilisation d'outils de plus en plus puissants. Prenez Ruby on rails, par exemple : c'est un framework d'une complexité extrême, mais il est très aisé de faire ses premiers pas avec lui. Rails est une réussite, car le principe de base de sa conception est la facilité d'usage. C'est une des raisons pour lesquelles CouchDB est reposant : découvrir CouchDB et comprendre ses principes fondamentaux devrait paraître naturel pour la plupart des personnes qui se sont penchées un tant soit peu sur le Web. Et c'est aussi assez simple à expliquer à des utilisateurs au profil non technique.
Ne pas entraver les créateurs quand ils tentent de construire des solutions spécialisées est en soi une fonctionnalité fondamentale et un souhait que CouchDB aime à satisfaire. Nous trouvons que les outils existants sont trop encombrants pour s'en accommoder durant les phases de développement et de production. C'est pourquoi nous avons décidé de faire de CouchDB une solution facile, voire plaisante à utiliser. Les chapitres 3Premiers pas et 4Les fondamentaux de l'API démontrent le caractère intuitif de l'API REST basée sur HTTP.
Le paramètre de production est un autre aspect de la relaxation procurée par CouchDB à ses utilisateurs. Si vous avez une application en production, CouchDB fait en sorte de ne pas vous déranger. Son architecture interne est tolérante aux pannes, les défaillances se produisent dans un environnement contrôlé et sont gérées harmonieusement. Les problèmes individuels ne se répandent pas en cascade à travers tout le système, mais demeurent isolés dans les requêtes.
Les concepts fondamentaux de CouchDB sont simples, puissants et bien compris. Les équipes d'exploitation (si vous en avez une ; à défaut, c'est vous) n'ont pas à s'inquiéter de comportements aléatoires et d'erreurs impossibles à retracer. Si quelque chose devait aller de travers, vous pourriez facilement localiser le problème, mais ces situations sont rares.
CouchDB est aussi conçu pour s'adapter aux variations de trafic. Par exemple, si un site web connaît un pic soudain de trafic, CouchDB absorbera généralement un grand nombre de requêtes concurrentes sans s'effondrer. Cela nécessitera peut-être plus de temps pour chaque requête, mais elles seront toutes satisfaites. Quand ce pic retombera, CouchDB recouvrera sa rapidité habituelle.
Le troisième motif de détente est relatif à l'attribution et au retrait de ressources matérielles sur lesquelles fonctionne votre application. C'est ce que l'on appelle usuellement le passage à l'échelle. CouchDB impose un ensemble de contraintes au programmeur. De prime abord, CouchDB peut paraître rigide, mais certaines fonctionnalités sont écartées à la conception, car leur inclusion mettrait en péril le passage à l'échelle de l'application qui les utiliserait. Nous détaillerons le passage à l'échelle dans la Partie IV, Déployer CouchDB.
En bref, CouchDB ne vous laisse pas faire ce qui pourrait vous causer des problèmes par la suite. Cela signifie que vous devrez parfois désapprendre les bonnes pratiques que vous avez déduites de vos expériences passées ou présentes. Le Chapitre 24,Recettes donne une liste des tâches courantes et explique comment les réaliser avec CouchDB.
I-B. Une manière différente de modéliser vos données▲
Nous croyons que CouchDB changera profondément la manière dont vous construisez des applications traitant des documents. CouchDB combine un modèle de stockage de documents intuitif à un moteur de requêtes puissant et si simple que vous demanderez peut-être pourquoi personne n'y a pensé avant.
« Django est peut-être conçu pour le Web, mais CouchDB est conçu par le Web. Je n'ai jamais vu de logiciel embrassant si profondément la philosophie sous-jacente à HTTP. CouchDB fait pâlir Django et le relègue à la « vieille école » de la même manière que Django relègue l'ASP au passé. »
— Jacob Kaplan-Moss, développeur de Django
CouchDB s'inspire grandement de l'architecture du Web et des concepts de ressources, de méthodes et de représentations. Il va plus loin en fournissant des moyens efficaces de requête, de sous-division, de fusion et de filtrage de vos données. Ajoutez-y la tolérance aux pannes, des capacités extrêmes de passage à l'échelle, des réplications incrémentales et CouchDB devient un nid douillet pour les bases de données orientées documents.
I-C. Une réponse plus adaptée aux applications courantes▲
Nous concevons des logiciels pour améliorer notre existence et celle des autres. Typiquement, cela consiste à prendre quelques informations banales (contacts, devis, factures) et à les manipuler à l'aide d'un ordinateur. CouchDB est une réponse adaptée aux applications courantes comme celles-ci, car il inclut aux origines de son modèle de données le concept naturel de documents évolutifs et autosuffisants.
I-C-1. Données autosuffisantes▲
Une facture contient toutes les informations décrivant une unique transaction : le vendeur, l'acquéreur, la date et une liste d'objets ou de services cédés. Comme le montre la Figure 1, Documents autosuffisants, il n'y a pas de référence abstraite dans ce document qui pointe vers un autre bout de papier qui contient le nom et l'adresse du vendeur. Les comptables apprécient la simplicité d'avoir tout au même endroit. Et, si le choix leur est donné, les développeurs aussi.

Et pourtant, recourir aux références est exactement la manière dont nous modélisons les données dans les bases de données relationnelles ! Chaque facture est stockée dans une table sous la forme d'un enregistrement qui référence d'autres enregistrements dans d'autres tables : un pour les informations concernant le vendeur, un pour chaque objet, et encore davantage pour le détail des objets, sans compter les informations du constructeur, et cetera desunt.
Il n'est pas question de dénigrer le modèle relationnel qui est largement adapté et extrêmement utile pour de nombreuses raisons. Toutefois, cela illustre la problématique des modèles de données qui ne correspondent pas à la manière dont les données sont traitées dans le monde réel.
Prenons le cas du carnet d'adresses pour illustrer une modélisation différente des données qui se rapproche davantage du monde réel : une pile de cartes de visite. Tout comme dans l'exemple des factures, une carte de visite contient toutes les informations importantes sur le même bout de carton. Nous appelons cela les données « autosuffisantes » et c'est un concept important pour comprendre les bases de données telles que CouchDB [NdT : en anglais, self-contained data].
I-C-2. Syntaxe et sémantique▲
La plupart des cartes de visite affichent les mêmes informations : l'identité de quelqu'un, une affiliation et quelques informations de contact. Malgré les divergences de présentation, les informations véhiculées sont les mêmes et nous identifions rapidement le bout de carton comme étant une carte de visite. En ce sens, nous pouvons dire d'une carte de visite qu'elle est un document du monde réel.
La carte de visite de Jan pourrait indiquer un numéro de téléphone, mais pas de numéro de fax, tandis que celle de J. Chris affiche les deux informations. Jan n'a pas à rendre ce manque d'information explicite en écrivant quelque chose de ridicule comme : « Fax : aucun » sur sa carte. Il préfère plutôt ne pas l'inscrire, ce qui signifie qu'il n'en a pas.
Nous pouvons constater que les documents du monde réel de même type, tels que les cartes de visite, ont une sémantique similaire (le type d'informations écrites), mais divergent grandement par la syntaxe, c'est-à-dire dans la manière dont ils sont structurés. Tout individu est habitué à gérer facilement ce genre de divergence.
Alors qu'une base de données relationnelle de type classique vous oblige à modéliser vos données a priori, le concept de documents sans squelette de CouchDB vous en affranchit en vous fournissant un moyen redoutable d'agréger vos données a posteriori, comme vous le feriez dans le monde réel. Nous détaillerons comment concevoir des applications avec ce paradigme de stockage sous-jacent.
I-D. Construire des îlots pour de grands systèmes▲
CouchDB est un système de stockage utile en lui-même. Vous pouvez bâtir de nombreuses applications avec les outils que CouchDB met à votre disposition. Mais CouchDB a un plus grand dessein. Ses composants peuvent être utilisés pour construire des îlots qui résolvent les problèmes de stockage de manière un tant soit peu différente pour les systèmes plus grands ou plus complexes.
Que vous ayez besoin d'un système qui soit extrêmement rapide aux dépens de la fiabilité (pensez à la journalisation) ou d'un système qui garantisse le stockage dans deux locaux différents aux dépens de la performance, CouchDB est votre atout.
Il existe de nombreux paramètres que vous pouvez ajuster pour rendre un système plus performant dans un domaine, mais vous allez nécessairement impacter négativement d'autres aspects. Nous décrirons un exemple au prochain chapitre : le théorème CAP (ou CDP ou théorème de Brewer en français). Pour avoir un aperçu des autres aspects qui affectent les systèmes de stockage, consultez les figures 2 et 3.
En réduisant la latence pour un système donné (ce qui ne se limite pas aux systèmes de stockages), vous impactez la parallélisation et la capacité de traitement.
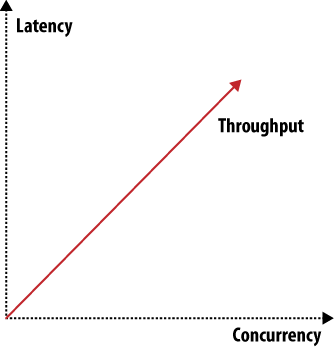
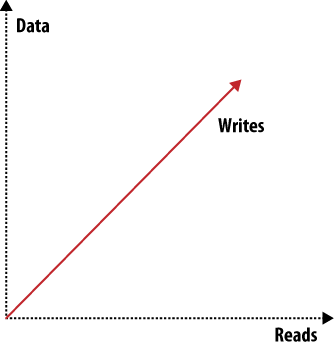
Quand vous voulez passer à l'échelle, il existe trois problématiques à aborder : dimensionner les requêtes de lecture, les requêtes d'écriture et les données. D'autres facteurs, comme la fiabilité ou la simplicité, s'ajoutent orthogonalement aux figures 2 et 3. Vous pouvez tracer de nombreux graphiques comme ceux-ci qui montrent combien les différents facteurs vont dans autant de directions différentes et caractériser ainsi le système auquel ils s'appliquent.
CouchDB est très flexible et vous permet de bâtir des îlots pour créer un système qui réponde parfaitement à votre problème. Cela ne signifie pas pour autant que CouchDB peut être ajusté pour répondre à tous les problèmes ; ici, pas de « balle en argent »,mais dans le domaine du stockage de données, il peut vous faire faire un joli bout de chemin en sa compagnie.
I-D-1. Mécanisme de réplication de CouchDB▲
Le mécanisme de réplication de CouchDB est l'un de ces îlots. Son rôle fondamental est de synchroniser au moins deux bases de données CouchDB. Cela peut paraître simple, mais la simplicité est un facteur clé pour permettre à la réplication de résoudre de nombreux problèmes : permettre de manière fiable la redondance des données entre plusieurs machines ; répartir les données dans un cluster de bases CouchDB qui partagent un sous-ensemble du nombre total de requêtes qui sont adressées au cluster (répartition de charge) ; répartir les données sur des sites différents, par exemple à Tokyo et à New York.
Le mécanisme de réplication de CouchDB exploite la même API REST que les clients. HTTP est omniprésent et bien compris. La réplication est incrémentale, ce qui signifie que, si vous perdez la connexion durant le transfert (ou quel que soit l'incident qui se produise), elle reprendra là où elle s'était arrêtée la dernière fois. En outre, elle transfère uniquement les données nécessaires à la synchronisation des deux bases de données.
Plutôt que de penser que tout ira bien. CouchDB pose toujours l'hypothèse que les choses peuvent aller de travers (comme la connexion réseau) et CouchDB est conçu pour récupérer harmonieusement ces erreurs. Le mécanisme de réplication incrémental en est une bonne illustration. L'idée que « tout peut aller de travers » est l'antidote des illusions de l'informatique distribuée :
- Le réseau est fiable ;
- Le temps de latence est nul ;
- La bande passante est infinie ;
- Le réseau est sûr ;
- La topologie du réseau ne change pas ;
- Il y a un et un seul administrateur réseau ;
- Le coût de transport est nul ;
- Le réseau est homogène.
Les outils existants tâchent souvent de cacher le fait qu'il y a un réseau et que tout ou partie des conditions précitées ne s'appliquent pas à leur usage. Cela conduit généralement à des plantages fatals quand un élément s'est mis de travers. À l'opposé, CouchDB ne tente pas de masquer le réseau : il réagit harmonieusement aux erreurs et vous fait savoir quand des actions sont nécessaires à votre niveau.
I-E. Les données locales sont reines▲
CouchDB tire quelques enseignements du Web, et il est une chose qui pourrait être améliorée dans le Web : la latence. Quand vous devez patienter pour qu'une application réponde ou qu'un site web s'affiche, vous attendez quasiment toujours à cause d‘un lien réseau trop faible pour vos besoins. Patienter quelques secondes au lieu de quelques millisecondes affecte grandement le ressenti de l'utilisateur.
Que faites-vous quand vous êtes déconnecté ? Cela arrive chaque fois que votre FAI rencontre des problèmes ou que votre iPhone, G1 ou BlackBerry ne capte pas le réseau ; et qui dit pas de connectivité dit aucun moyen de récupérer vos données.
CouchDB peut aussi s'employer dans de tels cas, et c'est là que le passage à l'échelle est de nouveau important. Cette fois, il s'agit de réduction. Imaginez que CouchDB soit installé sur les terminaux mobiles qui peuvent synchroniser leurs données avec des bases CouchDB centrales quand ils sont sur le réseau. La synchronisation ne connaît pas les contraintes d'interface utilisateur qui doivent réagir en moins d'une seconde. D'autre part, il est plus facile d'optimiser les systèmes pour une bande passante importante et une grande latence que pour une bande passante faible et des temps de réponses très rapides. Les applications embarquées peuvent alors exploiter CouchDB localement et, comme aucune connexion réseau n'est nécessaire pour cela, la latence est subséquemment faible.
Reste à savoir si vous pouvez vraiment utiliser CouchDB sur un téléphone. En fait, Erlang, le langage sur lequel repose CouchDB, a été conçu pour des systèmes bien plus petits et bien moins puissants que les téléphones actuels.
I-F. Conclusion▲
Le chapitre suivant explore plus avant le caractère distribué de CouchDB. Nous devrions avoir distillé suffisamment d'informations pour piquer votre curiosité. Allons-y !
II. Cohérence finale▲
Dans le chapitre précédent, nous avons vu que la flexibilité offerte par CouchDB nous permet de faire évoluer nos données à mesure que notre application se développe et se métamorphose. Dans ce chapitre, nous verrons en quoi la granularité de CouchDB sert la simplicité et nous permet de bâtir aisément des systèmes distribués et échelonnables.
II-A. Exploiter la granularité▲
Un système distribué est un système robuste qui s'exécute au travers d‘un vaste réseau. Une singularité de l'informatique distribuée tient en la possible disparition des liens réseau et il existe de nombreuses stratégies pour gérer ce type de segmentation. CouchDB se différencie en acceptant le principe de cohérence finale, par opposition à la garantie de cohérence absolue qui s'obtient au détriment de la disponibilité des données comme le font les SGDB relationnels ou Paxos. Ces systèmes ont de commun qu'ils considèrent que les données se comportent de manière différente quand plusieurs personnes y accèdent simultanément. Leur approche diffère selon qu'ils mettent l'accent sur la cohérence, la disponibilité ou la résistance au morcellement.
L'ingénierie des systèmes distribués est délicate. La plupart des pièges que vous rencontrerez au fil du temps ne sont pas évidents au départ. Nous n'avons pas toutes les solutions, et CouchDB n'est pas la panacée, mais quand vous travaillez avec la granularité de CouchDB plutôt que contre elle, vous pouvez naturellement concevoir des applications échelonnables.
Bien sûr, bâtir un système distribué n'est que le commencement. Un site web dont la base de données n'est accessible qu'une fois sur deux est à peu près inutile. Malheureusement, l'approche traditionnelle des bases de données relationnelles quant à la cohérence des données permet aux développeurs de s'appuyer sur un état global, sur des horloges globales et sur d'autres choses déconseillées, car peu sûres, sans même s'en apercevoir. Aussi, avant de détailler la manière dont CouchDB promeut le passage à l'échelle, nous allons décrire les contraintes auxquelles un système distribué est confronté. Dès que nous aurons vu les problèmes qui se posent lorsqu'une application ne peut pas compter sur l'omniprésence de ses modules, nous verrons que CouchDB fournit un moyen intuitif et efficace pour modéliser des applications hautement disponibles.
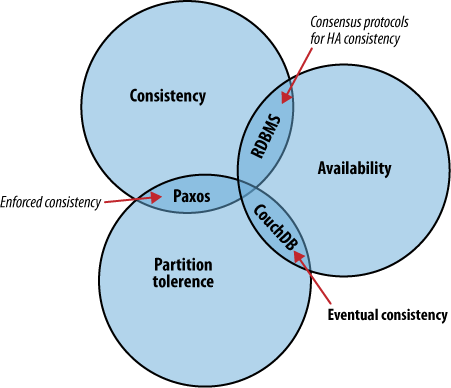
II-B. Le théorème de Brewer (ou théorème CAP ou théorème CDP)▲
Le théorème de Brewer définit quelques stratégies pour distribuer la logique applicative en différents points du réseau. CouchDB recourt au mécanisme de réplication pour propager les modifications entre les nœuds. C'est une approche très différente des algorithmes traditionnels et des bases de données relationnelles, lesquels placent le curseur à une autre intersection des courbes de cohérence, de disponibilité et de résistance au morcellement.
Le théorème de Brewer, illustré par la figure 1, Le théorème de Brewer, identifie trois problématiques distinctes :
La cohérence
- Tous les clients de la base de données voient les mêmes données, même en cas de mises à jour concurrentes ;
La disponibilité
- Tous les clients de la base de données peuvent accéder à une version des données ;
La résistance au morcellement
- La base de données peut être divisée et répartie sur plusieurs serveurs.
Quand un système croît au point qu'un seul nœud de la base de données est incapable de gérer la charge, une solution sensée est d'ajouter de nouveaux serveurs. Quand nous ajoutons des nœuds, nous devons nous interroger sur la répartition des données entre eux. Avons-nous des bases qui stockent exactement les mêmes données ? Mettons-nous différents jeux de données sur différents serveurs ? Laissons-nous uniquement certains serveurs écrire les données et d'autres, se contenter de lire ?
Quelle que soit l'approche que l'on choisit, nous devrons nous confronter à un problème commun : conserver la synchronisation entre ces serveurs de base de données. Si vous écrivez quelque information que ce soit sur un nœud, comment vous assurez-vous qu'une requête de lecture adressée à un autre serveur reflète ce dernier changement ? Ces événements pourraient se succéder à quelques millisecondes près. Même avec un petit nombre de serveurs, ce problème peut devenir d'une complexité extrême.
Lorsqu'il est absolument nécessaire que tous les clients accèdent à une vue cohérente des données, les utilisateurs d'un nœud devront attendre que tous les autres nœuds s'accordent avant de pouvoir effectuer l'opération de lecture ou d'écriture. Dans ce cas, nous voyons que la disponibilité subit le contrecoup de la cohérence. Cependant, il y a des situations dans lesquelles la disponibilité l'emporte sur la cohérence :
« Tout nœud d'un système devrait pouvoir prendre des décisions en se basant uniquement sur l'état local. Si vous avez besoin de quelque chose, que vous êtes sous pression, que des problèmes se produisent, et que vous devez obtenir un accord, vous êtes perdu. Si vous vous préoccupez du passage à l'échelle, tout algorithme qui vous force à obtenir un accord deviendra inexorablement votre goulot d'étranglement. Soyez-en certain. »
—Werner Vogels, Directeur de la technologie et Vice-président d'Amazon
Si la disponibilité est la priorité, nous pouvons laisser un client écrire sur un nœud de la base de données sans attendre l'accord des autres nœuds. Si la base de données est capable de réconcilier ces opérations avec les autres nœuds, nous obtenons une sorte de « cohérence finale » en échange de la haute disponibilité. Étonnamment, c'est un compromis souvent acceptable pour les applications.
À la différence des bases de données relationnelles, où chaque action effectuée est nécessairement sujette à des contrôles d'intégrité, CouchDB facilite la conception d'applications qui sacrifient la cohérence immédiate au profit de bien meilleures performances rendues possibles par une distribution simple.
II-C. Cohérence locale▲
Avant d'aborder le fonctionnement de CouchDB en cluster, il est important de comprendre le fonctionnement interne d'une seule instance de CouchDB. L'API CouchDB est conçue pour fournir une interface légère et pratique autour de la base. En regardant de plus près la structure du cœur de la base de données, nous aurons une meilleure compréhension de l'API qui l'entoure.
II-C-1. La clé de vos données▲
Au cœur de CouchDB se trouve un puissant moteur de stockage en B-Tree [NdT : arbre équilibré]. Un arbre B est une structure ordonnée qui permet la recherche, l'insertion et la suppression avec un temps de traitement logarithmique. Comme le montre la Figure 2, Anatomie d‘une requête sur une vue, CouchDB utilise ce moteur de stockage en arbre B pour toutes les données, documents et vues. Si nous en comprenons un, nous les comprendrons tous.
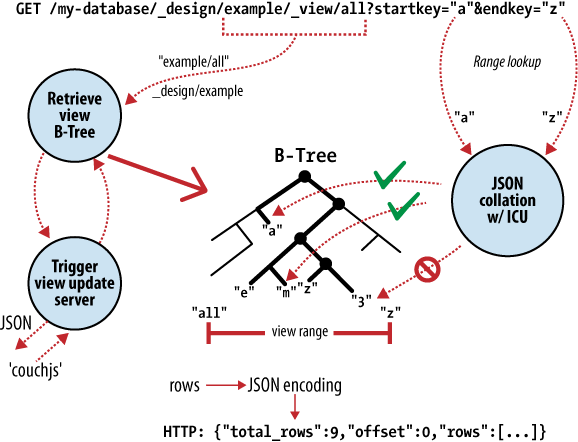
CouchDB utilise MapReduce pour trouver les résultats d'une vue. MapReduce utilise deux fonctions : subdiviser [NdT : map] et agréger [NdT : reduce] qui sont appliquées sur chaque document indépendamment des autres. Être à même de séparer ces deux opérations induit que le calcul d'une vue peut être parallélisé et permettre le calcul incrémental. Plus important encore, ces deux fonctions produisent un couple (clé,valeur), ce qui permet à CouchDB de stocker les résultats dans l'arbre B, trié par clé. Or, les recherches par clé, ou intervalle de clés, sont d'une rapidité redoutable dans un arbre B. Traduit en notation de complexité (O), cela donne respectivement O(log N) et O(log N + K).
Avec CouchDB, nous accédons aux documents et aux vues par clé ou intervalle de clés. C'est une correspondance directe avec les opérations sous-jacentes effectuées par le moteur de stockage en arbre B de CouchDB. En joignant les insertions et mises à jour de documents, cette correspondance directe explique que nous parlions de fine couche d'interface entourant le moteur de base de données pour décrire l'API.
Être capable d'accéder aux enregistrements uniquement à l'aide de leur clé est une capacité très importante qui nous permet d'obtenir des gains de performance impressionnants. En plus de ces gains colossaux de rapidité, nous pouvons répartir les données sur plusieurs nœuds sans perdre la faculté de lancer une requête sur chaque nœud indépendamment. BigTable, Hadoop, SimpleDB et memcached restreignent l'accès aux objets par leur seule clé pour ces mêmes raisons.
II-C-2. Absence de verrouillage▲
Une table dans une base de données relationnelle est une seule structure de données. Si vous voulez modifier une table, disons mettre à jour un enregistrement, le SGBD doit garantir que personne ne peut lire cet enregistrement qui est en cours de mise à jour. Le moyen classique de garantir cette exclusivité est de recourir à un verrou. Si plusieurs clients veulent accéder à la table, le premier seulement ferme le verrou, ce qui place tous les autres en attente. Quand la requête du premier client s'achève, l'accès au verrou est donné au deuxième tandis que les autres patientent, et ainsi de suite. Cette série d'exécutions successives de requêtes, même quand elles parviennent en parallèle au serveur, gaspille une quantité importante de la capacité de traitement de votre serveur de base de données. Soumise à une charge importante, une base de données relationnelle peut passer davantage de temps à chercher qui est autorisé à faire quoi, et dans quel ordre, qu'à véritablement traiter les données.
Plutôt que de recourir aux verrous, CouchDB utilise le Multi-Version Concurrency Control (MVCC) pour gérer les accès concurrents à la base. La Figure 3, MVCC ne signifie aucun blocage, illustre la différence entre MVCC et les mécanismes traditionnels de verrouillage. MVCC permet à CouchDB de tourner à plein régime, tout le temps, même soumis à une forte demande. Les requêtes sont exécutées en parallèle, exploitant à fond toute la capacité de calcul que le serveur peut offrir.

Dans CouchDB, les documents sont versionnés, à peu près comme ils le seraient dans un système de gestion de versions tel que Subversion. Si vous voulez changer une valeur dans un document, vous créez une toute nouvelle version de ce document et la sauvegardez en sus de la première. Cela fait, vous vous retrouvez avec deux versions du même document, une ancienne et une nouvelle.
En quoi cela est-il meilleur que le verrouillage ? Considérez un ensemble de requêtes de lecture du document. La première requête accède au document. Pendant que cette lecture est traitée, une deuxième requête modifie le document. Puisque la deuxième requête inclut une toute nouvelle version de celui-ci, CouchDB peut simplement l'ajouter à la base de données sans avoir à attendre que la requête de lecture s'achève.
Au moment où une troisième requête arrive pour lire ce même document, CouchDB va l'orienter vers la nouvelle version du document qui vient d'être écrite. Pendant ce temps, la première requête peut toujours lire le document original.
Une requête de lecture accédera toujours à la version la plus récente de votre base de données.
II-C-3. Validation▲
En tant que concepteurs d'applications, nous devons définir le type de données que nous acceptons en entrée et celles que nous refusons. La faculté d'expression de ce type de validation sur des données complexes au sein même d'un traditionnel SGBD laisse à désirer. Heureusement, CouchDB offre, dans la base de données, une puissante fonctionnalité permettant de créer des formulaires de validation par document.
CouchDB peut valider les documents à l'aide de fonctions JavaScript semblables à celles utilisées pour MapReduce. Chaque fois que vous tentez de modifier un document, CouchDB va appeler la fonction de vérification avec une copie du document existant, une copie du nouveau document et un ensemble d'informations complémentaires telles que l'identifiant de l'utilisateur. La fonction de validation peut ainsi accepter ou refuser la modification.
En tirant profit de la granularité de CouchDB, nous épargnons d'innombrables cycles CPU qui auraient été nécessaires pour sérialiser les graphes d'objets provenant de SQL, pour les convertir en objets du domaine et en exploitant ces objets pour effectuer une validation au niveau applicatif.
II-D. Cohérence distribuée▲
Maintenir la cohérence au sein d'un unique nœud de base de données est relativement simple pour la plupart des bases. Les réels problèmes surviennent lorsqu'il s'agit de faire la même chose entre plusieurs serveurs. Si un client écrit sur le serveur A, comment s'assurer que c'est cohérent avec le serveur B, ou C, ou D ? Pour les bases de données relationnelles, c'est un problème complexe, pour preuve les livres entiers qui traitent du sujet. Vous pourriez utiliser des topologies de réplication multimaître, maîtreesclave, partitionner, fragmenter, disposer des caches d'écriture et toutes sortes de techniques compliquées.
II-D-1. Réplication incrémentale▲
Puisqu'avec CouchDB les opérations s'effectuent toutes au niveau du document, si vous voulez utiliser deux nœuds, vous n'avez plus à vous inquiéter de les garder en communication permanente. CouchDB parvient à une cohérence finale entre les bases de données en recourant à la réplication incrémentale : un processus où les modifications des documents sont périodiquement copiées entre les serveurs. Nous sommes ainsi capables de construire un cluster dont les nœuds sont autosuffisants [NdT : shared-nothing cluster] et indépendants, ne laissant ainsi aucun point de contention dans le système.
Vous avez besoin d'absorber plus de charge avec un cluster CouchDB ? Il vous suffit d'ajouter un serveur.
Comme le montre la figure 4, Réplication incrémentale entre nœuds CouchDB, avec le mécanisme de réplication incrémentale, vous pouvez synchroniser vos données entre deux bases de données comme vous le voulez et quand vous le voulez. Après la réplication, chaque base de données est capable de travailler indépendamment.
Vous pourriez utiliser cette fonctionnalité pour synchroniser des serveurs dans un cluster ou entre vos centres de données à l'aide d'un programmateur de tâches tel que cron, ou encore avec votre ordinateur portable sur lequel vous travaillez dans le train. Chaque base de données peut être exploitée de manière classique et les modifications pourront être synchronisées ultérieurement dans les deux sens.
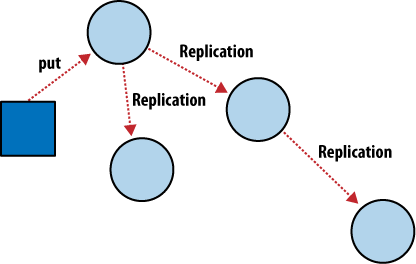
Que se passe-t-il quand vous modifiez le même document dans deux bases de données différentes et que vous voulez les synchroniser entre elles ? Le mécanisme de réplication de CouchDB est capable de détecter automatiquement les conflits et de les résoudre. Quand CouchDB détecte qu'un document a été modifié dans les deux bases de données, il y place un drapeau l'indiquant un conflit, comme le ferait un traditionnel système de gestion de versions.
Ce n'est pas aussi problématique que cela pourrait le paraître. Quand deux versions d'un document sont en conflit à l'occasion de la réplication, la version gagnante est sauvegardée comme étant la nouvelle version. Plutôt que de jeter la version perdante, comme vous pourriez le penser, CouchDB la sauvegarde comme une version antérieure dans l'historique du document. Ainsi, il vous est possible d'y accéder si vous en avez besoin. Cela se produit automatiquement et de manière cohérente, donc les deux bases feront le même choix.
Il vous appartient de gérer les problèmes d'une manière qui ait du sens pour votre application. Vous pouvez laisser les choses telles quelles, ou revenir à la version antérieure, ou tenter de fusionner les deux versions et sauvegarder le résultat.
II-D-2. Étude de cas▲
Greg Borenstein, un ami et collègue, a écrit une petite bibliothèque pour convertir les listes de lectures Songbird en objets JSON et a décidé de les stocker dans CouchDB pour les sauvegarder. Le logiciel final utilise MVCC de CouchDB et la gestion des versions de document pour garantir que les listes sont sauvegardées correctement entre les nœuds.
Songbird est un lecteur audiovisuel libre avec un navigateur intégré basé sur XULRunner de Mozilla. Songbird est disponible sur Microsoft Windows, Appel Mac OS X, Solaris et Linux.
Examinons le fonctionnement de cette application de sauvegarde. En premier lieu, du point de vue d'un utilisateur sauvegardant un seul ordinateur puis utilisant Songbird pour synchroniser les listes de lectures entre plusieurs ordinateurs. Nous verrons en quoi la gestion des versions des documents transforme un problème épineux en une solution qui fonctionne simplement.
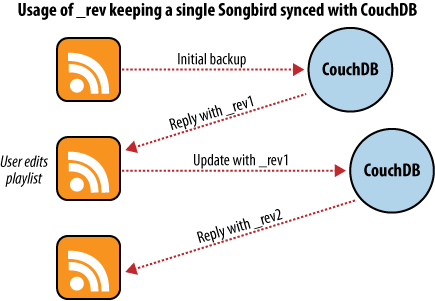
La première fois que nous utilisons ce logiciel de sauvegarde, nous y chargeons nos listes de lectures et initialisons la sauvegarde. Chaque liste est convertie en un objet JSON qui est envoyé à la base de données CouchDB. Comme l'indique la figure 5, Sauvegarde vers une seule base de données, CouchDB retourne l'identifiant du document et le numéro de version [NdT : revision number] de chaque liste quand il le stocke dans la base.
Quelques jours plus tard, nous réalisons que nos listes de lecture ont été mises à jour et que nous voulons sauvegarder nos modifications. Après avoir chargé nos listes dans le logiciel de sauvegarde, celui-ci va chercher la dernière version présente dans CouchDB ainsi que son numéro de version. Quand le logiciel retourne la nouvelle liste, CouchDB requiert que ce document soit intégré à la requête.
CouchDB s'assure ensuite que le numéro de version du document correspond à celui présent dans la base. Celui-ci est toujours mis à jour à chaque modification, donc si le numéro indiqué par le client ne correspond pas à celui présent dans la base, cela signifie que quelqu'un l'a mis à jour entretemps. Modifier un document après que quelqu'un d'autre l'ait déjà fait est généralement une mauvaise idée.
Obliger les clients à fournir le bon numéro de version est le cœur de la stratégie optimiste de CouchDB en termes de concurrence d'accès.
Nous avons maintenant un ordinateur portable que nous voulons synchroniser avec notre ordinateur de bureau. Avec toutes nos listes de lectures sur notre bureau, la première étape consiste à restaurer la sauvegarde du bureau. C'est la première fois que nous le faisons, donc notre ordinateur portable est à présent à niveau avec celui du bureau.
Après avoir édité notre liste de tangos argentins sur notre ordinateur portable pour y inclure de nouvelles musiques que nous avons achetées, nous voulons sauvegarder nos modifications. Le logiciel de sauvegarde remplace le document de la liste de lecture dans la base de données CouchDB du portable ; un nouveau numéro de version est généré. Quelques jours plus tard, nous nous souvenons de ces nouveaux morceaux et voulons les copier sur notre ordinateur de bureau. Comme le montre la figure 6, Synchronisation entre deux bases de données, le logiciel de sauvegarde copie le nouveau document et le nouveau numéro de version sur la base de l'ordinateur de bureau. Les deux bases de données sont désormais à niveau.
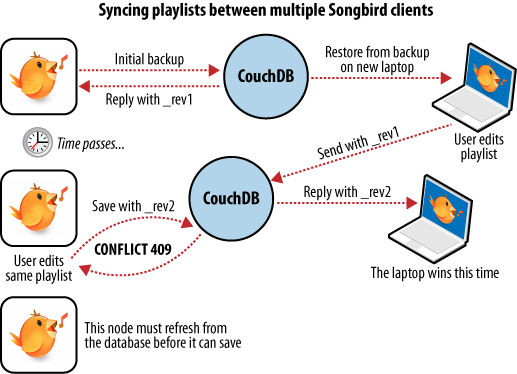
CouchDB garantit que ces mises à jour seront possibles uniquement si elles sont basées sur les informations courantes, car il conserve les différentes versions d'un document. Si nous avions fait des changements entre les deux synchronisations, les choses n'auraient pas été si simples.
Admettons que nous réalisions quelques changements sur nos listes du portable et oubliions de les synchroniser. Quelques jours plus tard, nous éditons les listes sur notre ordinateur de bureau, effectuons une sauvegarde et voulons la synchroniser avec le portable. Comme l'illustre la figure 7, Conflit de synchronisation entre deux bases de données, quand notre logiciel de sauvegarde tente de répliquer les deux bases de données, CouchDB se rend compte que les données envoyées par le bureau sont obsolètes et nous informe qu'il y a eu un conflit.
Corriger cette erreur est chose aisée d'un point de vue applicatif. Il suffit de télécharger la version de la liste de lecture et de permettre à l'utiliser de fusionner les modifications, ou de sauvegarder les modifications locales dans une nouvelle liste de lecture.

II-E. Conclusion▲
CouchDB s'inspire grandement de l'architecture du Web et des leçons apprises lors du déploiement de systèmes fortement distribués se basant sur celle-ci. En comprenant pourquoi cette architecture fonctionne comme cela et en apprenant à identifier quelles parties de votre application peuvent être facilement distribuées, mais aussi lesquelles ne le peuvent pas, vous améliorerez votre capacité à concevoir des applications distribuées et échelonnables, avec ou sans CouchDB.
Nous avons parcouru les principaux problèmes liés au modèle de cohérence de CouchDB et indiqué quelques bénéfices à en tirer quand vous travaillez dans le sens de CouchDB et non à son encontre. Mais voilà assez de théorie ! Démarrons l'engin et faisons fonctionner tout ça, qu'on voie de quoi il retourne !
III. Premiers pas▲
Dans ce chapitre, nous ferons un tour rapide des fonctionnalités offertes par CouchDB et nous familiariserons avec Futon, l'interface d'administration intégrée dans le moteur. Nous créerons notre premier document et testerons le concept de vues. Mais avant de commencer, référez-vous à l'annexe D, Installation depuis les sources et cherchez-y votre système d'exploitation. Vous devrez suivre les instructions qui s'y trouvent pour installer CouchDB avant de poursuivre la lecture de ce chapitre.
III-A. L'ensemble des systèmes est opérationnel !▲
Examinons l'Application Programming Interface (API) à l'aide de l'utilitaire en ligne de commande curl. Notez qu'il s'agit d'une manière parmi d'autres de s'adresser à CouchDB et que nous vous en indiquerons de nouvelles dans la suite de l'ouvrage. Ce qui est intéressant avec curl, c'est qu'il vous permet de forger votre requête HTTP et de voir ce qui se trouve « sous le capot » de votre base de données.Assurez-vous que CouchDB est démarré et exécutez :
curl http://127.0.0.1:5984/Cela envoie une requête de type GET à l'instance de CouchDB que vous venez d'installer.
La réponse devrait ressembler à :
{"couchdb":"Welcome","version":"0.10.1"}Pas très spectaculaire. CouchDB vous souhaite le bonjour et indique sa version.
Ensuite, nous pouvons lister les bases :
curl -X GET http://127.0.0.1:5984/_all_dbsLa seule chose que nous avons ajoutée à la requête précédente est la chaîne de caractères _all_dbs.
La réponse devrait ressembler à :
[]Ah ! oui ! nous n'avons pas encore créé de base de données. Nous récupérons donc une liste vide.
La commande curl envoie une requête GET par défaut. Vous pouvez produire des requêtes POST avec curl -X POST. Afin de nous y retrouver dans l'historique de la console, nous utilisons l'option -X même pour les requêtes de type GET. Par la suite, si nous voulons envoyer la requête en POST, il suffit de changer la méthode.
HTTP effectue davantage d'opérations « sous le capot » que celles que vous voyez ici. Si vous cherchez à voir tout ce qui passe sur le câble, ajouter l'option -v (c.-à-d. curl -vX GET) et vous verrez la tentative de connexion au serveur, les en-têtes de la requête et ceux de la réponse. Très utile pour déboguer !
Créons une base de données :
curl -X PUT http://127.0.0.1:5984/baseballCouchDB va répondre :
{"ok":true}La requête précédente de récupération de la liste des bases devient plus utile :
curl -X GET http://127.0.0.1:5984/_all_dbs
["baseball"]Le moment est propice pour évoquer JavaScript Object Notation (JSON), le format de données compris par CouchDB. JSON est un format d'échange de données léger basé sur la syntaxe de JavaScript. Puisque JavaScript est intégré à votre navigateur web, cela en fait un client idéal.
Les crochets ([]) dénotent une liste ordonnée et les accolades ({}) indiquent un tableau clé/valeur. Les clés doivent être des chaînes de caractères délimitées par des guillemets droits et doubles (") tandis que les valeurs peuvent être des chaînes de caractères, des nombres, des booléens, des listes ou des tableaux. Pour plus de détails, référez-vous à l'annexe E, Notions de JSON.
Créons une autre base de données :
curl -X PUT http://127.0.0.1:5984/baseballCouchDB va répondre :
{"error":"file_exists","reason":"The database could not be created, the file already exists."}Nous avons déjà une base qui porte ce nom, donc CouchDB nous renvoie une erreur. Recommençons en changeant le nom :
curl -X PUT http://127.0.0.1:5984/planktonCouchDB va répondre :
{"ok":true}Récupérons la liste des bases :
curl -X GET http://127.0.0.1:5984/_all_dbsCouchDB va répondre :
["baseball", "plankton"]Pour simplifier les choses, supprimons cette seconde base :
curl -X DELETE http://127.0.0.1:5984/planktonCouchDB va répondre :
{"ok":true}La liste des bases redevient celle d'avant :
curl -X GET http://127.0.0.1:5984/_all_dbsCouchDB va répondre :
["baseball"]Par souci de concision, nous passons sur l'exploitation des documents ; la prochaine section l'abordera avec un procédé plus simple. Dans les exemples qui suivent, gardez à l'esprit que ce qui est généré « sous le capot » correspond exactement à ce que vous venez de voir : tout est fait à l'aide de requêtes GET, PUT, POST, et DELETE sur une URI.
III-B. Bienvenue à bord de Futon▲
Après avoir vu l'API bas niveau de CouchDB, essayons-nous à Futon, l'interface d'administration intégrée dans le moteur. Futon permet d'exploiter toutes les fonctionnalités de CouchDB et rend aisée l'utilisation des fonctionnalités avancées. À l'aide de Futon, nous pouvons créer et détruire des bases de données, consulter et éditer des documents, créer et parcourir les vues MapReduce et déclencher la réplication entre les bases de données.
Pour accéder à Futon depuis votre navigateur web, allez sur :
http://127.0.0.1:5984/_utils/Si vous utilisez la version 0.9 ou supérieure, vous devriez voir quelque chose ressemblant à la figure 1, La page d'accueil de Futon. Dans les chapitres suivants, nous nous intéresserons à l'exploitation de CouchDB par les langages côté serveur tels que Ruby ou Python. Pour lors, ce chapitre est l'occasion rêvée de montrer un exemple d'application web servie directement par le serveur web intégré dans CouchDB ; chose qui peut vous intéresser pour vos propres applications.
La première chose à faire avec une nouvelle installation de CouchDB est d'exécuter la chaîne de tests pour vérifier que tout fonctionne bien. Cela vous garantit que les problèmes qui pourraient se poser ne sont pas dus à un problème d'installation. De plus, un test qui échoue signale qu'il y a des éléments à vérifier dans notre installation avant de tenter d'utiliser un serveur qui est peut-être vrillé. Cela nous évite de nous poser la question plus tard, lorsque les choses tournent mal.
Certains paramétrages du réseau (souvent rencontrés) causent l'échec du test de réplication quand il est lancé à partir de localhost. Vous pouvez contourner ce problème en vous adressant à http://127.0.0.1:5984/_utils/.
Rendez-vous sur la chaîne de tests en cliquant sur « Test Suite » dans le menu latéral, puis cliquez sur « run all » en haut pour démarrer les tests. La Figure 2, La chaîne de tests en cours d'exécution dans Futon illustre Futon en action.

Puisque la chaîne de tests est exécutée depuis le navigateur, elle garantit à la fois que CouchDB fonctionne correctement et que la connexion de votre navigateur à la base de données est bien configurée, ce qui peut s'avérer utile pour diagnostiquer les problèmes de serveur mandataire ou d'autres intermédiaires HTTP.
Si les résultats de la chaîne de tests indiquent un grand nombre d'erreurs, reportez-vous à l'annexe D, Installation depuis les sources pour trouver comment réparer votre installation.
Une fois les tests achevés, vous avez vérifié que CouchDB est opérationnel et vous êtes prêt à voir ce que Futon peut vous offrir.
III-C. Votre première base de données et votre premier document▲
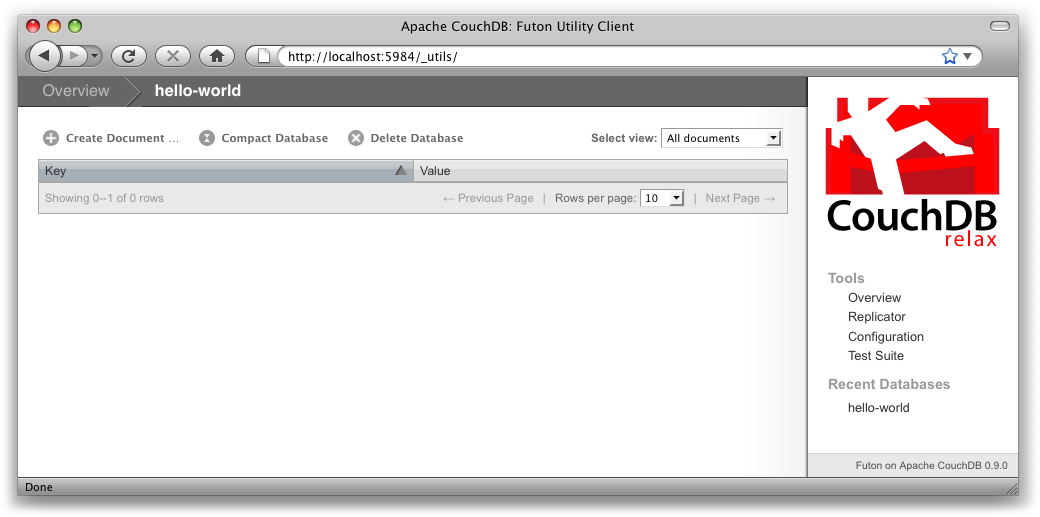
Créer une base de données avec Futon est simple : depuis la page de synthèse, cliquez sur « Create database » . Saisissez ensuite le nom, ici hello-world, et cliquez sur le bouton « Create » .
Une fois votre base créée, Futon affiche la liste de tous les documents qu'elle contient. Au début, elle est vide (Figure 3, Une base de données vide dans Futon), donc créons notre premier document. Cliquez sur « Create document » et sur le bouton « Create » de la fenêtre modale [NdT : pop up]. Prenez garde de laisser l'identifiant du document vide, car CouchDB va générer un UUID pour vous.
Pour les besoins de la démonstration, l'UUID déterminé par CouchDB suffit. Toutefois, quand vous créez votre premier programme, nous vous encourageons à assigner vos propres UUID. En effet, si vous laissez le soin au serveur de générer vos UUID, que votre première requête est annulée et que vous la renvoyez, il est possible que vous génériez deux UUID et que vous ne receviez que le second. En assignant vos propres UUID, vous serez certain d'éviter la duplication d'un document.
Futon va afficher le document qui vient d'être créé, avec les seuls champs _id et _rev. Pour ajouter un champ, cliquez sur le bouton « Add field ». Nommons-le hello. Cliquez sur l'icône verte (ou pressez « entrée » ) pour finaliser l'opération. Double-cliquez sur la colonne présentant la valeur de hello (positionnée par défaut à null) pour l'éditer.
Si vous tentez de positionner la nouvelle valeur à world, vous obtiendrez une erreur après avoir cliqué sur l'icône verte. C'est normal : dans CouchDB, les valeurs doivent être saisies au format JSON. Saisissez plutôt "world" (avec les guillemets droits et doubles), soit une chaîne de caractères valide en JSON. Vous pouvez tester les autres valeurs, par exemple [1, 2, "c"] ou {"foo":"bar"}. Une fois les valeurs saisies, relevez la valeur de l'attribut _rev et cliquez sur « Save Document ». Le résultat devrait avoisiner celui de la Figure 4, Un « hello world » avec Futon.
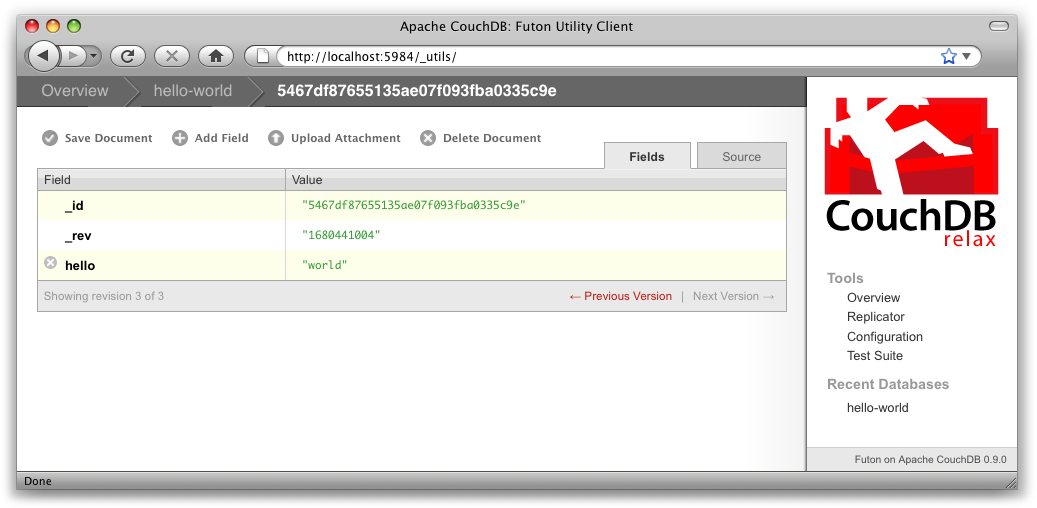
Vous noterez que la révision du document a changé (_rev). Nous détaillerons cela dans un autre chapitre. Pour le moment, il est suffisant de se rappeler que _rev agit comme un garde-fou durant la sauvegarde. Tant que CouchDB et vous-même êtes d'accord sur le dernier _rev d'un document, vous pouvez sauvegarder vos changements.
Futon permet aussi d'afficher les données JSON directement, ce qui peut s'avérer plus compact et plus facile à lire selon les données que vous traitez. Pour consulter la version JSON de notre « hello world » , cliquez sur l'onglet « Source » . Vous devriez avoir quelque chose ressemblant à la Figure 5, La forme JSON du document « hello world » avec Futon.

III-D. Exécuter une requête avec MapReduce▲
Les bases de données relationnelles courantes vous permettent d'exécuter n'importe quelle requête tant que vos données sont structurées convenablement. De son côté, CouchDB exploite des fonctions map (subdiviser) et reduce (agréger) dans un style connu sous le nom de MapReduce. La combinaison de ces fonctions offre une grande souplesse, car elles peuvent s'adapter aux variations de la structure d'un document. De plus, les index de chaque document peuvent être calculés de manière indépendante et en parallèle. Cette combinaison forme ce que CouchDB appelle une vue.
Pour les développeurs accoutumés aux bases de données relationnelles, MapReduce est une approche qui peut nécessiter un temps d'adaptation. Plutôt que de déclarer quels enregistrements de quelles tables doivent apparaître dans le résultat de la requête et de laisser au moteur de la base le choix du meilleur moyen de les obtenir, les requêtes d'agrégation (reduce) se basent sur des intervalles des clés générées par la fonction de subdivision (map).
La fonction de subdivision (map) est appelée une fois par document et reçoit celui-ci en argument. La fonction peut alors choisir d'ignorer le document ou d'émettre un ou plusieurs enregistrements sous la forme de couples clé/valeur. Les fonctions de subdivision ne doivent pas dépendre d'éléments externes au document. Cette indépendance est ce qui permet à CouchDB de générer les vues de manière incrémentale et en parallèle.
Dans CouchDB, les vues sont stockées comme des enregistrements qui sont triés par leur clé. Il est ainsi possible de retourner rapidement les enregistrements correspondants à un intervalle de clés, même avec des millions d'enregistrements stockés. Lorsque vous écrivez une fonction d'agrégation, votre but premier est de construire un index qui affecte une clé qui a du sens pour trouver la donnée qui se trouve derrière cette clé.
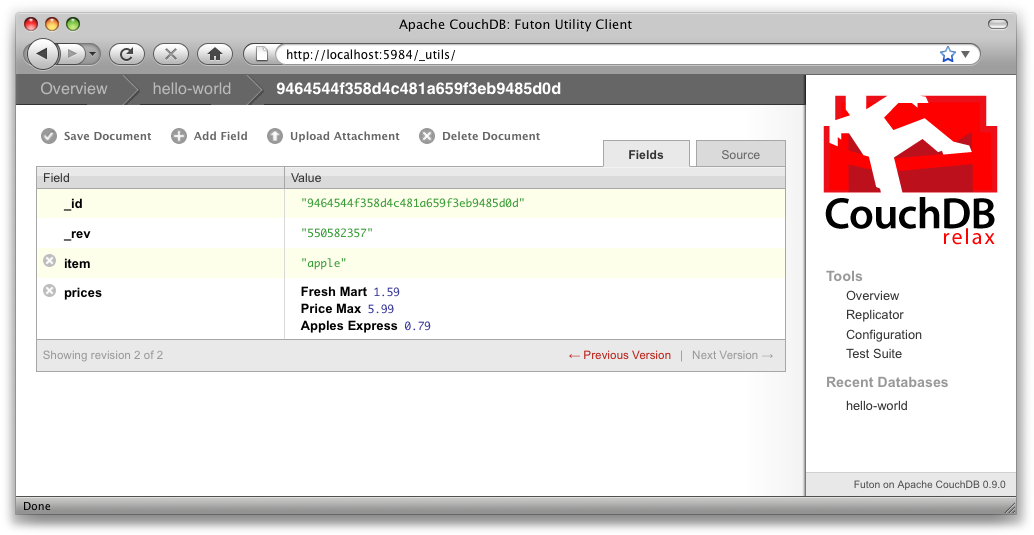
Avant de pouvoir tester une vue MapReduce, nous avons besoin de quelques données sur lesquelles opérer. Nous allons donc créer des documents stockant le prix d'articles de supermarché comme on en trouve dans divers magasins. Faisons-le pour les pommes, les oranges et les bananes (laissez CouchDB générer les champs _id et _rev). Utilisez Futon jusqu'à obtenir un résultat similaire à :
{
"_id" : "bc2a41170621c326ec68382f846d5764",
"_rev" : "2612672603",
"item" : "apple",
"prices" : {
"Fresh Mart" : 1.59,
"Price Max" : 5.99,
"Apples Express" : 0.79
}
}Ce document devrait ressembler à la Figure 6, Un document contenant le prix des pommes dans Futon.
Parfait ! Maintenant que c'est fait, créons les oranges :
{
"_id" : "bc2a41170621c326ec68382f846d5764",
"_rev" : "2612672603",
"item" : "orange",
"prices" : {
"Fresh Mart" : 1.99,
"Price Max" : 3.19,
"Citrus Circus" : 1.09
}
}Et enfin les bananes :
{
"_id" : "bc2a41170621c326ec68382f846d5764",
"_rev" : "2612672603",
"item" : "banana",
"prices" : {
"Fresh Mart" : 1.99,
"Price Max" : 0.79,
"Banana Montana" : 4.22
}
}Imaginez que nous préparions un banquet, mais que le client soit très sensible au prix. Pour trouver les prix les plus bas, nous allons créer notre première vue qui montrera chaque fruit trié par prix. Cliquez sur « hello-world » pour revenir à l'écran de synthèse, puis dans le menu « select view », choisissez « Temporary view ». Vous devriez obtenir quelque chose de similaire à la Figure 7, Une vue temporaire dans Futon.
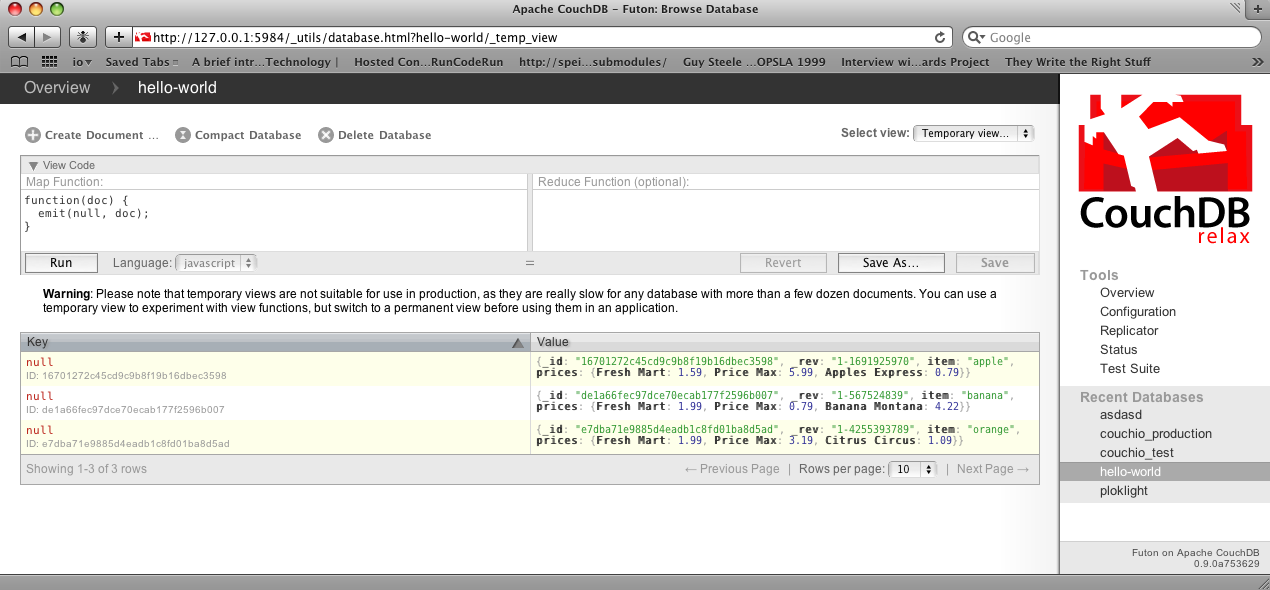
Éditez la fonction de subdivision (map) pour qu'elle contienne :
function(doc) {
var store, price, value;
if (doc.item && doc.prices) {
for (store in doc.prices) {
price = doc.prices[store];
value = [doc.item, store];
emit(price, value);
}
}
}Il s'agit d'une fonction JavaScript que CouchDb exécute sur chacun des documents et qui génère la vue. Nous laissons la fonction d'agrégation (reduce) vide pour le moment.
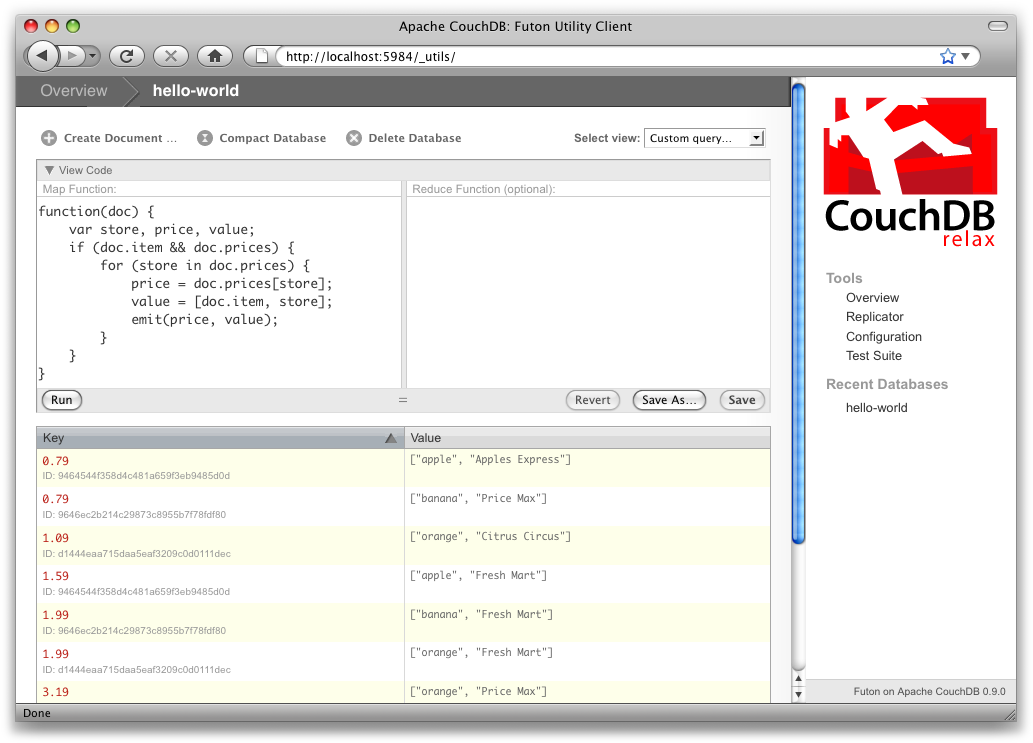
Cliquez sur « Run » et vous devriez voir les enregistrements comme sur la Figure 8, Les résultats d'une vue avec Futon, c'est-à-dire avec les objets triés par prix. Cette fonction d'agrégation pourrait être plus utile si elle regroupait les objets par type pour que les prix des bananes soient à côté les uns des autres. L'algorithme de tri des clés de CouchDB permet d'avoir n'importe quel tableau JSON dans la clé. Dans notre cas, nous allons créer un tableau de la forme [item, price] (objet, prix) pour que CouchDB regroupe les résultats par type et prix.
Modifions la vue :
function(doc) {
var store, price, key;
if (doc.item && doc.prices) {
for (store in doc.prices) {
price = doc.prices[store];
key = [doc.item, price];
emit(key, store);
}
}
}Ici, nous vérifions tout d'abord que le document contient les champs que nous voulons utiliser. CouchDB ne s'inquiète pas de quelques erreurs dans l'exécution de la fonction d'agrégation, mais quand l'échec est récurrent (que ce soit à cause d'un champ manquant ou d'une exception JavaScript), CouchDB cesse d'indexer pour éviter de consommer des ressources. C'est pourquoi il est nécessaire de vérifier l'existence des champs avant de les utiliser. Dans notre cas, la fonction d'agréation ignorera le premier document que nous avons créé tout à l'heure, cela en n'émettant aucun enregistrement ni aucune erreur. Le résultat de la requête devrait être similaire à ce que présente la Figure 9, Vue résultante après avoir regroupé par type et prix.
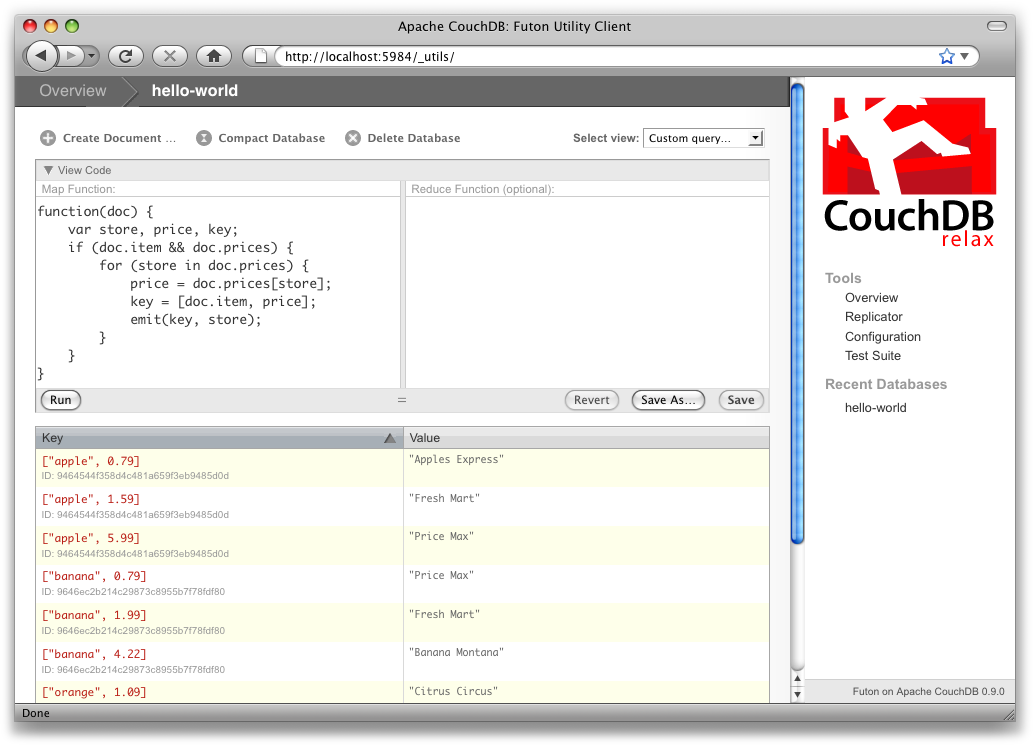
Une fois que nous avons confirmé que nous traitons un document qui contient un type d'objet et quelques prix, nous parcourons les prix pour émettre des couples clé/valeur. La clé est un tableau contenant l'objet et le prix, et définit l'index trié de CouchDB. La valeur sera ici le nom de l'enseigne où l'objet peut être trouvé à ce prix.
Les enregistrements d'une vue sont triés par leur clé - dans cet exemple, d'abord par objet, puis par prix. Cette méthode de tri complexe est essentielle pour créer des index utiles avec CouchDB.
Utiliser MapReduce peut-être difficile, tout particulièrement si vous avez l'habitude des bases de données relationnelles. Ce qui importe, c'est de se rappeler que les fonctions de subdivision (map) vous permettent de trier les données en utilisant la clé qui vous convient, et que CouchDB s'attelle à fournir un accès rapide et efficace aux données dans un intervalle de clés.
III-E. Déclencher la réplication▲
Futon peut déclencher la réplication entre deux bases de données locales, entre une base locale et une distante, ou entre deux bases distantes. Nous allons voir comment répliquer les données d'une base locale vers une autre, ce qui est un moyen simple de faire une sauvegarde.
Tout d'abord, nous devons créer une base de données vide pour pouvoir y répliquer les données. Revenez à l'écran de synthèse et créez une base hello-replication. Maintenant, cliquez sur « Replicator » dans le menu latéral et sélectionnez hello-world comme source et hello-replication comme destinataire. Cliquez sur « Replicate » pour déclencher la réplication. Vous devriez obtenir quelque chose ressemblant à Figure 10, Déclencher une réplication avec Futon.
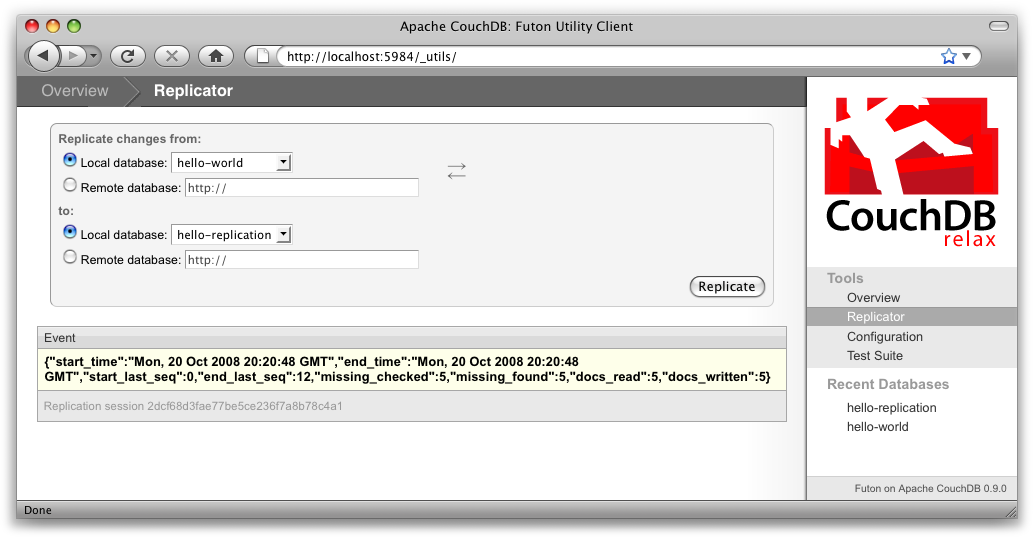
Pour d'imposantes bases de données, la réplication peut prendre beaucoup plus de temps. Il est essentiel de garder la fenêtre du navigateur ouverte durant la réplication. Alternativement, vous pouvez la déclencher à l'aide de curl ou d'un autre client HTTP capable de gérer les connexions de longue durée. Si vous fermez la connexion avant la fin de la réplication, vous devrez la relancer. Heureusement, CouchDB reprendra là où il s'était arrêté plutôt que de reprendre au début.
III-F. Résumé▲
Maintenant que vous avez un aperçu des principales fonctionnalités de Futon, vous êtes parés à explorer vos données pendant qu'au fil des chapitres suivants nous concevrons notre exemple d'application. L'approche « tout JavaScript » de Futon pour la gestion de CouchDB montre qu'il est possible de bâtir une application web complète en utilisant uniquement l'API HTTP de CouchDB et son serveur web intégré.
Mais avant cela, nous allons détailler plus précisément l'API HTTP de CouchDB. « Curlons-nous » sur le sofa et détendons-nous.
IV. Les fondamentaux de l'API▲
Ce chapitre explore en détail l'API de CouchDB. Il aborde les choses sérieuses et les astuces, de même que les bonnes pratiques ; il aide à éviter les embûches.
Nous commencerons par revoir les opérations de base décrites dans le chapitre précédent et profiterons de cette occasion pour aller plus en profondeur. Nous montrerons aussi ce que Futon doit incorporer dans sa partie « métier » pour nous fournir ces fonctionnalités ravissantes.
Ce chapitre est à la fois une introduction aux fondamentaux de l'API de CouchDB et une référence. Si vous ne parvenez pas à vous souvenir comment exécuter telle requête, ou pourquoi certains paramètres sont requis, vous pouvez toujours vous référer à ce chapitre (nous sommes nous-même certainement le premier utilisateur de ce chapitre).
Pour expliquer chaque détail de l'API, nous avons parfois besoin d'expliquer aussi le raisonnement qui le sous-tend. Nous saisissons ces occasions pour vous expliquer pourquoi CouchDB se comporte ainsi.
L'API peut être catégorisée de la manière suivante. Nous explorerons chacune des catégories :
- Serveur ;
- Bases de données ;
- Documents ;
- Réplication.
IV-A. Serveur▲
Cette requête est simple et basique. Elle peut permettre de vérifier que CouchDB est lancé. Elle peut aussi permettre à certaines bibliothèques de vérifier la version du moteur. Nous utilisons de nouveau l'outil curl :
curl http://127.0.0.1:5984/CouchDB répond, tout heureux de participer :
{"couchdb":"Welcome","version":"0.10.1"}Vous récupérez une chaîne de caractères JSON qui, transformée en un objet natif ou une structure de données de votre langage de programmation, vous permet d'accéder aux deux chaînes que sont la bienvenue et la version.
Ce n'est pas d'une utilité folle, mais cela illustre bien la manière dont CouchDB se comporte. Vous envoyez une requête HTTP et vous recevez une chaîne JSON dans la réponse HTTP.
IV-B. Bases de données▲
Faisons quelque chose d'un peu plus utile : créons des bases de données. Pour les puristes, CouchDB est un système de gestion de bases de données (SGBD). Cela signifie qu'il peut accueillir plusieurs bases de données. Une base de données est un conteneur qui stocke des données corrélées ; nous reviendrons sur ce que cela signifie. Dans la pratique, les termes se recouvrent : on parle couramment d'un SGBD comme d'une « base de données » et réciproquement. Il se peut que nous suivions cette tendance, aussi ne vous en formaliserez-vous pas. De manière générale, le contexte est explicite et indique si nous parlons du système CouchDB dans son entièreté ou d'une seule base de données.
Bref, créons-en une ! Nous voulons stocker nos albums de musique préférés, aussi nommons-nous notre base, de manière très inventive, albums. Notez que nous utilisons à nouveau l'option -X pour dire à curl d'envoyer une requête de type PUT plutôt qu'une requête de type GET comme il le ferait par défaut.
curl -X PUT http://127.0.0.1:5984/albumsCouchDB répond :
{"ok":true}C'est fait ! Vous venez de créer une base de données et CouchDB vous indique que tout s'est bien passé. Que se passe-t-il si vous tentez de créer une base de données qui existe déjà ? Essayons :
curl -X PUT http://127.0.0.1:5984/albumsCouchDB répond :
{"error":"file_exists","reason":"The database could not be created, the file already exists."}Nous obtenons une erreur ; voilà qui est pratique. Nous en apprenons aussi un peu plus sur la manière dont CouchDB fonctionne : il stocke chaque base de données dans un seul fichier. Très simple. Cela n'est pas sans conséquence, mais passons sur les détails pour le moment, car nous explorerons le système de stockage sous-jacent dans l'Annexe F, La force des arbres-B.
Créons une nouvelle base de données, cette fois avec l'option -v (pour verbose = détaillée) de curl. Cette option invite curl à nous montrer tous les détails de la requête et de la réponse :
curl -vX PUT http://127.0.0.1:5984/albums-backupcurl affiche :
* About to connect() to 127.0.0.1 port 5984 (#0)
* Trying 127.0.0.1... connected
* Connected to 127.0.0.1 (127.0.0.1) port 5984 (#0)
> PUT /albums-backup HTTP/1.1
> User-Agent: curl/7.16.3 (powerpc-apple-darwin9.0) libcurl/7.16.3 OpenSSL/0.9.7l zlib/1.2.3
> Host: 127.0.0.1:5984
> Accept: */*
>
< HTTP/1.1 201 Created
< Server: CouchDB/0.9.0 (Erlang OTP/R12B)
< Date: Sun, 05 Jul 2009 22:48:28 GMT
< Content-Type: text/plain;charset=utf-8
< Content-Length: 12
< Cache-Control: must-revalidate
<
{"ok":true}
* Connection #0 to host 127.0.0.1 left intact
* Closing connection #0Quel bavard ! Expliquons ligne après ligne pour comprendre ce qu'il se passe et relevons ce qui est important. Quand vous aurez vu ce type d'affichage quelques fois, vous repérerez plus vite l'essentiel.
* About to connect() to 127.0.0.1 port 5984 (#0)curl nous dit qu'il est sur le point d'établir la connexion TCP avec le serveur CouchDB que nous avons spécifié dans notre URI. Pas très important, sauf lors de la résolution de problèmes réseau.
* Trying 127.0.0.1... connected
* Connected to 127.0.0.1 (127.0.0.1) port 5984 (#0)curl indique qu'il s'est bien connecté à CouchDB. Sauf en cas de problèmes réseau, ce n'est pas important non plus.
Les lignes suivantes commencent toutes par les caractères > et <. > signifie que la ligne a été envoyée à CouchDB (sans le >) ; < signifie que la ligne a été reçue par curl.
> PUT /albums-backup HTTP/1.1Cela initialise la requête HTTP. Sa méthode [NdT : « Dans le protocole HTTP, une méthode est une commande spécifiant un type de requête, c'est-à-dire qu'elle demande au serveur d'effectuer une action. » Wikipédia ] est PUT, son URI est /albums-backup et la version du protocole HTTP est HTTP/1.1. Il existe aussi HTTP/1.0, qui peut s'avérer plus simple dans certains cas, mais pour des raisons pratiques, vous devriez utiliser HTTP/1.1.
Ensuite, nous voyons plusieurs en-têtes. Ils permettent d'adjoindre des informations à la requête.
> User-Agent: curl/7.16.3 (powerpc-apple-darwin9.0) libcurl/7.16.3 OpenSSL/0.9.7l zlib/1.2.3L'en-tête User-Agent indique à CouchDB quel client est utilisé pour envoyer la requête HTTP. Nous n'apprenons rien de nouveau : c'est curl. Cet en-tête est souvent utilisé pour différencier les clients avec lesquels des problèmes de compatibilité sont connus et pour lesquels la réponse devra être différente. Il aide aussi à déterminer la plateforme de l'utilisateur. Cette information peut être utilisée à des fins statistiques ou techniques. Pour CouchDB, l'en-tête User-Agent n'importe pas.
> Host: 127.0.0.1:5984L'en-tête Host est requis par HTTP 1.1. Il indique l'origine de la requête.
> Accept: */*L'en-tête Accept indique à CouchDB que curl accepte tous les types de médias. Nous verrons par la suite en quoi il est utile.
>Une ligne vide indique que la partie des en-têtes de la requête est terminée et que la suite contient les données que nous envoyons au serveur. Dans ce cas, nous n'envoyons pas la moindre donnée, donc le reste de l'affichage de curl concerne la réponse HTTP.
< HTTP/1.1 201 CreatedLa première ligne de la réponse HTTP envoyée par CouchDB inclut la version du protocole HTTP (pour permettre le traitement de son format), un code d'état et un message d'état. Des requêtes différentes appellent des réponses différentes. Il en existe une ribambelle qui indique au client (curl dans notre cas) quel effet a eu la requête, que ce soit un succès ou un échec. La RFC 2616 (spécifiant HTTP 1.1) définit le comportement à avoir selon le code d'état. CouchDB se conforme parfaitement à cette RFC.
Le code 201 Created indique au client que la ressource qu'il a sollicitée a été créée. Aucune surprise ici, mais si vous vous souvenez du code d'erreur que nous avons eu quand nous avons tenté de recréer une base de données existante, vous savez qu'il aurait pu en être tout autrement. Réagir aux réponses en se basant sur le code d'état est une pratique courante. Par exemple, tous les codes supérieurs ou égaux à 400 signalent une erreur. Si vous vouliez simplifier votre logique de traitement et réagir immédiatement à une erreur, vous pourriez simplement vérifier si le code d'état est >= 400.
< Server: CouchDB/0.10.1 (Erlang OTP/R13B)L'en-tête Server est pratique pour les diagnostics. Il indique quelle version de CouchDB et quelle version sous-jacente d'Erlang sont utilisées. En général, vous pouvez ignorer cet en-tête, mais c'est bon à savoir si vous en avez besoin.
< Date: Sun, 05 Jul 2009 22:48:28 GMTL'en-tête Date vous indique l'heure du serveur. Puisque les horloges du client et du serveur ne sont pas nécessairement synchronisées, cet en-tête est une simple information. Vous ne devriez pas bâtir d'applications sur ce critère !
< Content-Type: text/plain;charset=utf-8L'en-tête Content-Type indique le type MIME du corps de la réponse HTTP ainsi que son jeu de caractères. Nous savons déjà que CouchDB renvoie des chaînes de caractères JSON. Le Content-Type approprié est donc application/json. Alors pourquoi voyons-nous text/plain ? C'est là que le pragmatisme l'emporte sur le purisme. Envoyer un en-tête avec Content-Type positionné à application/json à un navigateur va déclencher l'option de téléchargement plutôt que d'afficher le contenu. Puisqu'il est très utile de pouvoir tester CouchDB depuis un navigateur, CouchDB indique text/plain, ce qui fait que tous les navigateurs affichent le JSON comme un texte.
Il existe quelques greffons qui influent sur le comportement de votre navigateur vis-à-vis du JSON, mais ils ne sont pas installés par défaut.
Vous rappelez-vous de l'en-tête Accept qui était positionné à \*/\* -> */* pour dire quel type MIME nous intéressait ? Si vous envoyez Accept: application/json dans votre requête, CouchDB sait que vous pouvez exploiter une réponse purement JSON avec le Content-Type adéquat ; il l'utilisera donc à la place de text/plain.
< Content-Length: 12L'en-tête Content-Length indique simplement combien d'octets composent le corps de la réponse.
< Cache-Control: must-revalidateL'en-tête Cache-Control vous indique, à vous ou à tout serveur mandataire qui se trouverait sur le chemin du serveur CouchDB, que la réponse ne doit pas être stockée en antémémoire (cached en anglais).
<Cette ligne vide sépare l'en-tête du corps du message.
{"ok":true}Nous avons déjà vu cela auparavant.
* Connection #0 to host 127.0.0.1 left intact
* Closing connection #0Dans ces deux dernières lignes, curl nous indique qu'il a conservé la connexion TCP ouverte pendant un moment, mais qu'il l'a fermée après avoir reçu toute la réponse.
Dans les chapitres suivants, nous verrons quelques requêtes avec l'option -v, mais nous omettrons certains en-têtes décrits ici pour ne laisser que ceux qui sont utiles dans les cas abordés.
C'est bien beau de créer une base de données, mais comment la supprime-t-on ? Tout simplement en changeant la méthode HTTP :
> curl -vX DELETE http://127.0.0.1:5984/albums-backupCela supprime la base de données. La requête va supprimer le fichier qui stocke le contenu de la base. Il n'y a pas de sécurité de type « Êtes-vous certain ? » ni de magie de type « Vider la corbeille » pour supprimer une base. Faites attention en utilisant cette commande. Vos données seront effacées sans aucune possibilité de retour en arrière si vous n'avez pas de sauvegarde.
Dans cette section, nous nous sommes penchés sur HTTP et avons posé les bases pour évoquer le reste de l'API CouchDB. Prochain arrêt : les documents !
IV-C. Documents▲
Dans CouchDB, le document est la structure de données de base. L'idée derrière la notion de document est, aussi surprenant que cela puisse paraître, un document du monde réel, c'est-à-dire un morceau de papier tel qu'une facture, une recette ou une carte de visite. Nous savons déjà que CouchDB utilise le format JSON pour stocker les documents. Voyons maintenant comment ce stockage fonctionne à bas niveau.
Tout document dans CouchDB a un ID (identifiant). Cet identifiant est unique pour une base de données. Vous pouvez choisir l'ID qui vous convient, mais pour de meilleurs résultats, nous vous recommandons un UUID (ou GUID), c'est-à-dire un identifiant universel (ou global) unique [NdT : Universally (or Globally) Unique IDentifier]. Les UUID sont des nombres aléatoires avec une faible probabilité de collision et il est possible d'en générer des milliers à la minute pendant des millions d'années sans doublons. C'est un bon moyen de garantir que deux personnes indépendantes ne peuvent pas créer deux documents différents avec le même identifiant. Pourquoi devriez-vous vous préoccuper de ce que quelqu'un d'autre est en train de faire ? Tout d'abord, cette autre personne pourrait être vous par la suite (plus tard ou sur un autre ordinateur). Ensuite, le mécanisme de réplication de CouchDB vous permet de partager des documents avec autrui et recourir aux UUID garantit que ça va fonctionner. Bref ! Nous reviendrons sur ce sujet par la suite. Pour le moment, créons quelques documents :
curl -X PUT http://127.0.0.1:5984/albums/6e1295ed6c29495e54cc05947f18c8af -d '{"title":"There is Nothing Left to Lose","artist":"Foo Fighters"}'CouchDB répond :
{"ok":true,"id":"6e1295ed6c29495e54cc05947f18c8af","rev":"1-2902191555"}La commande curl peut apparaître complexe, alors expliquons-la. Tout d'abord, -X PUT dit à curl de forger une requête de type PUT. S'ensuit une URL qui indique l'adresse IP et le port de votre instance de CouchDB. La ressource incluse dans l'URL (/albums/6e1295ed6c29495e54cc05947f18c8af) indique la position du document dans notre base de données albums. La suite alphanumérique barbare est notre UUID. Cet UUID est donc l'ID du document. Enfin, le paramètre -d ordonne à curl d'utiliser la suite comme corps de la requête PUT. La chaîne est une structure JSON simple incluant les attributs de titre et d'artiste avec leur valeur respective.
Si vous ne savez pas générer votre UUID, vous pouvez demander à CouchDB d'en générer un (en fait, c'est ce que nous venons de faire sans vous le montrer). Pour cela, envoyez une requête GET à /_uuids :
curl -X GET http://127.0.0.1:5984/_uuidsCouchDB répond :
{"uuids":["6e1295ed6c29495e54cc05947f18c8af"]}Voilà un UUID. Si vous en voulez plus, ajoutez le paramètre ?count=10 à la requête HTTP et vous en obtiendrez 10. Bien sûr, vous pouvez préciser le nombre qui vous convient.
Pour s'assurer que CouchDB ne nous ment pas en disant avoir sauvegardé notre document (il n'a pas pour habitude de mentir), tentez de le récupérer avec une requête GET :
curl -X GET http://127.0.0.1:5984/albums/6e1295ed6c29495e54cc05947f18c8afNous espérons que vous distinguez les différents éléments de la requête ici. Toute chose dans CouchDB a une adresse, une URI, et vous pouvez utiliser diverses méthodes HTTP pour agir sur ces URI.
CouchDB répond :
{"_id":"6e1295ed6c29495e54cc05947f18c8af","_rev":"1-2902191555","title":"There is Nothing Left to Lose","artist":"Foo Fighters"}Cela ressemble beaucoup au document que nous avons soumis à CouchDB ; tant mieux ! Mais vous devriez aussi noter que CouchDB a ajouté deux champs à votre structure JSON. Le premier est _id qui stocke l'UUID que nous avons spécifié. Nous connaissons toujours l'identifiant d'un document, ce qui est très pratique (si le champ est retourné par la vue). Le deuxième est _rev qui signifie numéro de version [NdT : revision number en anglais].
IV-C-1. Versions▲
Pour modifier un document dans CouchDB, vous n'allez pas lui dire de trouver tel document, de sélectionner tel champ et d'insérer telle valeur. Non, vous allez récupérer le document, modifier la structure JSON (ou l'équivalent dans votre langage de programmation) comme bon vous semble et sauvegarder le tout avec un nouveau numéro de version. Chaque modification est identifiée par une nouvelle valeur de _rev.
Pour mettre à jour ou supprimer un document, CouchDB exige que vous incluiez le champ _rev de la version concernée. Quand CouchDB accepte la modification, il génère un nouveau numéro de version. Ce mécanisme garantit que si quelqu'un d'autre a effectué un changement entretemps, vous devez récupérer la dernière version du document avant de pouvoir soumettre votre mise à jour. CouchDB n'acceptera pas votre requête autrement, puisque vous pourriez altérer ou effacer des données dont vous ignorez l'existence. En un mot comme en cent : celui qui modifie le document en premier a gagné. Voyons ce qui se passe si nous ne fournissons pas le champ _rev (ce qui revient à fournir un document obsolète) :
curl -X PUT http://127.0.0.1:5984/albums/6e1295ed6c29495e54cc05947f18c8af -d '{"title":"There is Nothing Left to Lose","artist":"Foo Fighters","year":"1997"}'CouchDB répond :
{"error":"conflict","reason":"Document update conflict."}Si vous voyez cela, ajoutez le dernier numéro de version à votre document dans la structure JSON :
curl -X PUT http://127.0.0.1:5984/albums/6e1295ed6c29495e54cc05947f18c8af -d '{"_rev":"1-2902191555","title":"There is Nothing Left to Lose", "artist":"Foo Fighters","year":"1997"}'Maintenant, vous comprenez pourquoi il était utile que CouchDB renvoie ce _rev quand nous avons soumis la première requête. CouchDB répond :
{"ok":true,"id":"6e1295ed6c29495e54cc05947f18c8af","rev":"2-2739352689"}CouchDB a accepté votre opération d'écriture et a aussi généré un nouveau numéro de version. Ce numéro correspond à l'empreinte MD5 du document sous sa forme transportable adjointe d'un préfixe N-, lequel indique le nombre de fois qu'un document a été mis à jour. C'est très utile pour la réplication. Référez-vous au Chapitre 17, Gestion des conflits pour de plus amples informations.
Il y a plusieurs raisons pour lesquelles CouchDB utilise ce système de gestion de versions, aussi appelé Multi-Version Concurrency Control (MVCC). Chacune d'elles est liée à l'autre et nous tenons l'occasion rêvée pour en expliquer quelques-unes.
L'un des aspects du protocole HTTP que CouchDB exploite est qu'il est sans états. Qu'est-ce que cela veut dire ? Quand vous échangez avec CouchDB, vous devez formuler des requêtes. Pour ce faire, vous devez ouvrir une connexion réseau avec CouchDB, échanger des octets et fermer la connexion. C'est ce qui se passe à chaque fois que vous soumettez une requête. D'autres protocoles permettent d'ouvrir une connexion, d'échanger des octets, de conserver la connexion ouverte, d'échanger à nouveau des octets - qui peuvent dépendre de ceux que vous avez déjà reçus - puis, en fin de compte, fermer la connexion. Maintenir une connexion ouverte pour pouvoir gérer des opérations futures nécessite plus de travail de la part du serveur. Ce qui se fait habituellement, c'est que durant la « vie » d'une connexion, le client conserve une vue cohérente et statique des données du serveur. Aussi, gérer un grand nombre de connexions parallèles induit une charge de travail significative. De leur côté, les connexions HTTP sont traditionnellement courtes et fournir les mêmes garanties s'avère beaucoup plus facile. En conséquence, CouchDB peut gérer beaucoup plus de connexions concurrentes.
Une autre raison pour laquelle CouchDB utilise MVCC est que son modèle est conceptuellement plus simple et donc plus facile à programmer. CouchDB nécessite moins de code pour fonctionner, ce qui est toujours une bonne chose puisque le ratio de source d'erreur par ligne de code est constant.
Le système de versions a aussi un impact positif sur les mécanismes de réplication et de stockage, mais nous y reviendrons plus tard dans le livre.
Le mot de version [NdT : en anglais, version or revision] peut vous être familier - si vous programmez sans système de gestion de versions, laissez tomber ce livre et apprenez à en utiliser un. Utiliser une nouvelle version lors d'une modification de document est semblable à un système de gestion de versions, mais il y a une différence notable : CouchDB ne garantit pas que les anciennes versions sont conservées.
IV-C-2. Passer les documents à la loupe▲
Maintenant, regardons de plus près nos requêtes de création de documents avec le paramètre -v de curl qui s'était avéré utile pour détailler l'API. C'est aussi une bonne occasion de créer des documents que nous pourrons réutiliser dans nos exemples à venir.
Ajoutons quelques-uns de nos albums de musique préférés. Récupérez un nouvel UUID à partir de la ressource /_uuids. Si vous ne vous souvenez plus comment faire, reculez de quelques pages.
curl -vX PUT http://127.0.0.1:5984/albums/70b50bfa0a4b3aed1f8aff9e92dc16a0 -d '{"title":"Blackened Sky","artist":"Biffy Clyro","year":2002}'Soit dit en passant, si vous en savez davantage sur votre album favori, n'hésitez pas à ajouter de nouvelles propriétés. Et ne vous inquiétez pas de connaître ces mêmes propriétés pour l'ensemble des albums, car le concept de documents sans squelette de CouchDB vous permet de stocker uniquement ce que vous connaissez. Après tout, vous devriez vous détendre et ne pas vous soucier de vos données.
Maintenant, avec le paramètre -v, la réponse de CouchDB (tronquée pour ne laisser que ce qui nous importe), ressemble à ceci :
> PUT /albums/70b50bfa0a4b3aed1f8aff9e92dc16a0 HTTP/1.1
>
< HTTP/1.1 201 Created
< Location: http://127.0.0.1:5984/albums/70b50bfa0a4b3aed1f8aff9e92dc16a0
< Etag: "1-2248288203"
<
{"ok":true,"id":"70b50bfa0a4b3aed1f8aff9e92dc16a0","rev":"1-2248288203"}Nous retrouvons le code d'état 201 Created dans les en-têtes de la réponse, comme nous l'avons vu précédemment lors de la création d'une base de données. L'en-tête Location nous donne l'URI complète vers le nouveau document. Et il y a un nouvel en-tête. Dans la terminologie HTTP, un « Etag » identifie une version spécifique d'une ressource. Dans ce cas, cela identifie la version spécifique (la première) et notre nouveau document. Voilà qui sonne agréablement à vos oreilles ? Oui, conceptuellement, un « Etag » correspond au numéro de version du document dans CouchDB, et cela ne devrait pas vous paraître surprenant que CouchDB utilise ses numéros de version comme « Etag ». Les « Etag » sont utiles pour les infrastructures d'antémémoire [NdT : caching en anglais]. Nous apprendrons à les utiliser dans le Chapitre 8, fonctions d'affichage.
IV-C-2-a. Pièces jointes▲
Avec CouchDB, les documents peuvent avoir des pièces jointes tout comme un courriel le peut. Une pièce jointe est identifiée par un nom et spécifie son type MIME (ou Content-Type) ainsi que le nombre d'octets qui le composent. Les pièces jointes peuvent être de n'importe quel type de données. Il est plus facile de se représenter les pièces jointes comme des fichiers liés à un document. Ces fichiers peuvent être du texte, des images, des documents Word [NdT : plutôt Open Office ;)], de la musique ou des films. Créons-en un.
Les pièces jointes obtiennent leur propre URL où vous pouvez télécharger les données. Disons que vous voulez adjoindre la jaquette de l'album au document 6e1295ed6c29495e54cc05947f18c8af (« There is Nothing Left to Lose »), et disons qu'elle se trouve dans un fichier artwork.jpg du répertoire courant :
> curl -vX PUT http://127.0.0.1:5984/albums/6e1295ed6c29495e54cc05947f18c8af/ artwork.jpg?rev=2-2739352689 --data-binary @artwork.jpg -H "Content-Type: image/jpg"Le paramètre -d@ dit à curl de transmettre le contenu du fichier dans le corps de la requête HTTP. Nous utilisons le paramètre -H pour indiquer à CouchDB que nous envoyons un fichier JPEG. CouchDB va conserver cette information et enverra l'en-tête approprié quand nous récupérerons cette pièce jointe. Dans le cas d'une image JPEG, le navigateur va l'afficher plutôt que vous inviter à l'enregistrer sur votre disque. Cela se révélera utile par la suite. Notez aussi que vous devez fournir le numéro de version du document auquel vous attachez la pièce jointe, puisque joindre une pièce, c'est modifier le document.
Vous devriez maintenant voir la jaquette si vous pointez votre navigateur sur http://127.0.0.1:5984/albums/6e1295ed6c29495e54cc05947f18c8af/artwork.jpg.
Si vous rapatriez à nouveau le document, vous verrez un nouveau champ :
curl http://127.0.0.1:5984/albums/6e1295ed6c29495e54cc05947f18c8afCouchDB répond :
{"_id":"6e1295ed6c29495e54cc05947f18c8af","_rev":"3-131533518","title": "There is Nothing Left to Lose","artist":"Foo Fighters","year":"1997","_attachments":{"artwork.jpg":{"stub":true,"content_type":"image/jpg","length":52450}}}_attachments est une liste de clés et de valeurs où les valeurs sont des objets JSON contenant les métadonnées des pièces jointes. stub=true nous précise que l'entrée ne contient que les métadonnées. Si nous utilisions l'option HTTP ?attachments=true dans notre requête, nous obtiendrions une chaîne encodée en base 64 contenant les données de la pièce jointe.
Nous aurons l'occasion de découvrir d'autres options de requêtes de même que d'autres fonctionnalités de CouchDB telles que la réplication, que nous allons aborder maintenant.
IV-D. Réplication▲
Le mécanisme de réplication de CouchDB permet de synchroniser des bases de données. Tout comme rsync synchronise deux répertoires locaux ou sur un réseau, la réplication synchronise deux bases locales ou distantes.
Dans une requête de type POST, vous indiquez à CouchDB la source et la destination [NdT : target dans le code] d'une réplication. CouchDB va trouver quels documents et quelles nouvelles versions se trouvent dans la source et sont absentes de la base de destination pour les transférer.
Nous nous attarderons davantage sur les détails de la réplication dans un autre chapitre ; ici, nous allons simplement vous montrer comment vous en servir.
En premier lieu, nous allons créer une base de données. Notez que CouchDB ne créera pas automatiquement la base de données de destination et renverra une erreur de réplication si elle n'existe pas (il en va de même pour la source, mais c'est une erreur plus difficile à commettre).
curl -X PUT http://127.0.0.1:5984/albums-replicaDésormais, nous pouvons utiliser la base albums-replica comme destination de la réplication :
curl -vX POST http://127.0.0.1:5984/_replicate -d '{"source":"albums","target":"albums-replica"}'Dès la version 0.11, CouchDB accepte l'option "create_target":true dans la chaîne JSON envoyée en POST à l'URL _replicate. Il créera ainsi automatiquement la base de données destinatrice si elle n'existe pas.
CouchDB répond (nous avons formaté la sortie pour la lire plus facilement) :
{
"history": [
{
"start_last_seq": 0,
"missing_found": 2,
"docs_read": 2,
"end_last_seq": 5,
"missing_checked": 2,
"docs_written": 2,
"doc_write_failures": 0,
"end_time": "Sat, 11 Jul 2009 17:36:21 GMT",
"start_time": "Sat, 11 Jul 2009 17:36:20 GMT"
}
],
"source_last_seq": 5,
"session_id": "924e75e914392343de89c99d29d06671",
"ok": true
}CouchDB conserve un historique des sessions de réplication. La réponse à une requête de réplication contient cet historique pour la session de réplication. Il est aussi important de noter que la connexion portant la requête de réplication demeurera ouverte jusqu'à ce que la réplication soit achevée. Si vous avez de nombreux documents, l'opération prendra du temps et vous n'obtiendrez pas de réponse tant que tous les documents ne seront pas répliqués. Un autre point important à relever est que le mécanisme de réplication s'applique uniquement aux modifications qui avaient eu lieu lors de la réception de la requête. Aussi, tout ajout ou modification ultérieurs au démarrage de la réplication ne seront pas répliqués.
Nous attirons aussi votre attention sur le "ok": true à la fin qui nous signale que tout s'est bien passé. Si vous consultez la base albums-replica, vous devriez voir tous les documents que vous avez créés dans la base albums. Sympa, hein ?
Ce que vous venez de faire s'appelle une réplication locale dans la terminologie de CouchDB. Vous avez créé une copie locale de votre base de données. C'est pratique pour les sauvegardes ou pour conserver un instantané [NdT : en anglais, snapshot] de votre base à une date donnée ou dans un état que vous désirez pouvoir retrouver plus tard. Vous pouvez être intéressé par cette solution si vous développez une application et que vous voulez pouvoir revenir en arrière, à un état stable de votre code et de vos données.
Il y a d'autres types de réplication utiles dans d'autres cas. Les éléments source et destination de la requête de réplication sont en fait des liens (comme en HTML). Pour lors, nous nous sommes limité à des liens relatifs à notre instance de CouchDB (donc locaux). Vous pouvez aussi indiquer une base de données distante :
curl -vX POST http://127.0.0.1:5984/_replicate -d '{"source":"albums","target":"http://127.0.0.1:5984/albums-replica"}'Utiliser une base source locale et une base destinataire distante est appelée une réplication propulsée [NdT : pushed replication en anglais]. Nous propulsons les changements vers un serveur distant.
Puisque nous n'avons pas encore de deuxième serveur CouchDB disponible pour le moment, nous allons simplement utiliser l'adresse complète (absolue) de notre serveur, mais vous devriez pouvoir faire de même avec un serveur distant.
C'est parfait pour partager des modifications locales avec des serveurs distants ou des voisins.
Vous pouvez aussi utiliser une source distante et une destination locale pour faire une réplication tractée. C'est parfait pour récupérer les dernières mises à jour d'un serveur utilisé par d'autres personnes.
curl -vX POST http://127.0.0.1:5984/_replicate -d '{"source":"http://127.0.0.1:5984/albums-replica","target":"albums"}'Enfin, vous pouvez exécuter une réplication à distance, ce qui s'avère utile pour les opérations de gestion :
curl -vX POST http://127.0.0.1:5984/_replicate -d '{"source":"http://127.0.0.1:5984/albums","target":"http://127.0.0.1:5984/albums-replica"}'CouchDB et REST
CouchDB se vante d'avoir une API qui adhère au modèle REST, mais ces requêtes de réplication ne semblent pas être vraiment de type REST pour un œil exercé. Qu'en est-il vraiment ? Si les parties de l'API liées à la base de données, aux documents et aux pièces jointes se conforment à REST, ce n'est pas le cas de toute l'API de CouchDB. L'API de réplication est un exemple parmi d'autres ; nous les verrons dans la suite de l'ouvrage.
Pourquoi mélangeons-nous les API typées REST ou non REST ? Est-ce que les développeurs sont trop fainéants pour se conformer partout au modèle REST ? Rappelez-vous que REST est un type qui se prête à certaines architectures (comme la partie de l'API qui traite les documents), mais que ce n'est pas la panacée. Déclencher un événement comme une réplication n'a pas de sens dans l'univers REST. Cela ressemble davantage à un appel de procédure distante. Et cette différence n'est en aucun cas problématique.
Nous croyons plutôt en l'adage qui veut que l'on utilise le bon outil pour les bonnes tâches, et REST ne peut pas répondre à tous les besoins. Nous nous rassurons au souvenir des propos de Leonard Richardson et de Sam Ruby qui partagent ce point de vue dans RESTful Web Services (publié par O'Reilly).
IV-E. Résumé▲
Ce qui précède n'est pas encore toute l'API de CouchDB, mais nous en avons vu l'essentiel en détail. Nous reviendrons sur ceux que nous avons passés ici sous silence au fil des besoins. Pour l'instant, nous vous jugeons prêt à bâtir des applications avec CouchDB.
V. Remerciements Developpez▲
Nous remercions toute l'équipe de rédaction ayant contribué à cette publication et particulièrement à Winjerome pour sa gabarisation. Un grand merci également à pierruel et à Claude LELOUP pour leurs corrections orthographiques.
